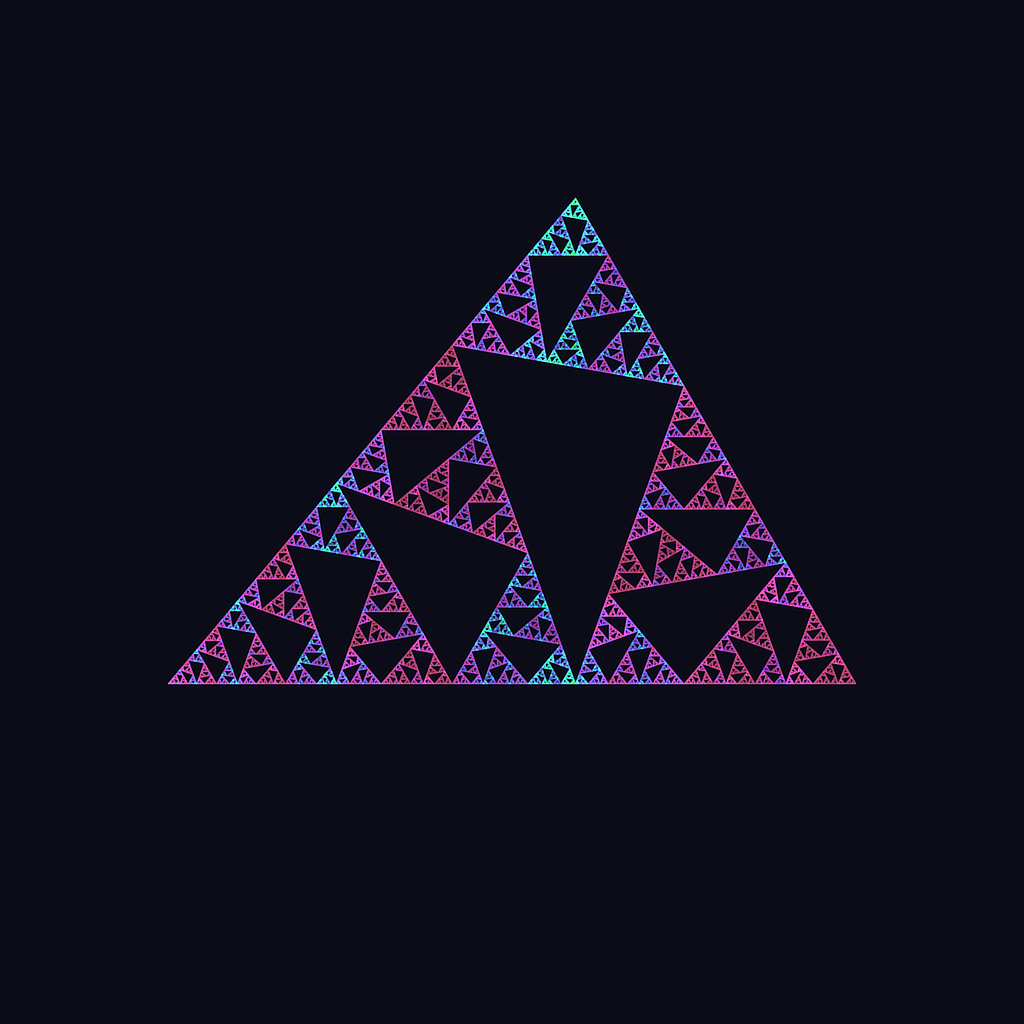Enter fullscreen mode for the full fullscreen experience
Author: Matigekunstintelligentie
-

Posters and Canvasses
The past few months I’ve been experimenting with printing my work. On canvasses, posters and even masks. Figuring out how many dots per image are needed, which colours work, which parts are cut or folded. Here are some gifts I gave to people that doubled as little experiments.

A2 poster HD 
User designed mask 
60x60cm canvas 40x40cm canvas 
Backside of canvas 
For those interested, here’s a list of works that are currently available. Some featured in my blogs and some from a blog post in the making. More works can be found on my Instagram @matigekunstintelligentie. Expect more algorithms in my blogs that allow you to make your own art pieces! Have any questions or want to commission me? Email me at matigekunstintelligentie@gmail.com!
-

Ideophones part II
In a previous blog, I asked the question of whether names are somehow connected with certain faces. CLIP projects text and images to the same latent space. I decided to see what happens if the names Karen and Kevin are projected into the StyleGAN2 latent space and then visualised by the generator. I must admit that the samples are slightly cherry-picked. Entering a single name is a slight abuse of the method which normally expects a little more elaborate description. Nevertheless, enjoy!

Kevin 
Also Kevin
Kevin has experienced some shit. Probably due to the self-fulfilling prophecy of Kevinism. In the previous blog on ideophones, the figure on the right was also named Kevin only second to Damien. Neither of these Kevin’s look like the Kevin that I have in mind.

Karen I pity the manager this Karen is talking to. I also wondered what Matige Kunstintelligentie personified would look like. Note that CLIP is trained in English and that these Dutch words will unlikely be part of the vocabulary. English is very easily tokeniseable whereas Dutch has compound words like Kunstintelligentie. I wonder whether that has a significant impact on Dutch NLP.

Matige Kunstintelligentie This technique of generating faces with CLIP and StyleGAN2 from names definitely needs some polishing work. As stated before this is not the intended use of CLIP. However, with a labeled dataset it could be done. If someone is willing to (legally) scrape some database with names I will happily train the model that does this. Then we might truly find out who is most Karen or Kevin.
-

The Museum of all Shells
How did I make the interpolation at the end? A magician never reveals his secrets. Luckily I’m no magician. The answer is quite simple: I trained a StyleGAN2 model. When I trained the model I had, and as of writing still have, a single 1080 GTX. The 8GB memory on this machine has caused me quite some trouble with training. The stats on Nvidia’s original GitHub page also aren’t very encouraging. They estimate that it would cost 69 days and 23 hours of training on the FFHQ dataset in configuration-f with a single Tesla V100 GPU. The 1080 GTX has less memory and 69 days is a bit much. What to do? How about transfer learning?
The concept of transfer learning is simple. A network spends most of its time learning about low-level features. These low-level features are similar across many imaging tasks. So instead of training a network from scratch, we leverage the effort that has already been put in training the low-level features on another dataset, in this case, FFHQ, and train on another dataset. This dataset can anything you like, but keep in mind that you’ll need quite a bit of data. FFHQ has 70k images! Recently a new paper call ‘Training Generative Adversarial Networks with Limited Data‘ came out, which might help if you don’t have a lot of data. This will likely be the topic of a future blog.
In my case, the dataset came from a paper called ‘A shell dataset, for shell features extraction and recognition‘ by Zhang et al. Hats of to Springer Nature for making science publicly accessible for a change. The data can be downloaded here. The dataset needs some cleaning. Using some simple thresholding I centered each image and removed the background. There’s another problem: FFHQ images have a resolution of 1024×1024, but these images are way smaller. Even in this day and age, people are taking low-resolution photos, unfortunately, presumably to save disk space or to annoy data scientists. I ended up upscaling the images with an AI technique, I don’t remember which one but any will do. Now that we have the data I’ll introduce the code.
Nvidia’s ProGAN/StyleGAN papers are brilliantly executed but an eye-sore to look at code-wise (to me at least). The codebase is fairly involved compared to other ML projects. It’s long, has some custom CUDA functions, and is written in TensorFlow. I tried TensorFlow in 2016, had a terrible time, switched to Pytorch, and never looked back. If TensorFlow is your thing then go to Nvidia’s official repository (you will need to clone this repository anyway so you might as well check it out) and follow the instructions there. I will be using Rosalinity’s implementation. You can read through Rosalinity’s instructions instead if you want, besides some minor tweaks it says the exact same.
First, you need to create a Lightning Memory-Mapped Database (LMDB) file from your data. As described in the repository you can generate multiple image sizes. I only need 1024×1024 images. The dataset path is the path to your dataset (who would have thought) and the LMDB path is where the resulting file will be stored. All this information is also available on Rosalinity’s repository. One thing it doesn’t say though is that your dataset folder must contain subfolders with data. If you pass a folder without another folder inside it, it will think the folder has no images.
python prepare_data.py --out LMDB_PATH size 1024 DATASET_PATHDownload the FFHQ f configuration .pkl file from the Nvidia repository and also clone the repository. Use the following command to convert the weight from pickle to Pytorch format. ~/stylegan2 refers to the Nvidia repository.
python convert_weight.py --repo ~/stylegan2 stylegan2-ffhq-config-f.pklNormally you’d now start generating faces and nothing is holding you back from doing so, but I want shells not faces. To get shells we train on the shell LMDB file. Compared to the training command from Rosalinity you’ll only need to change three things: the checkpoint, model size, and batch size. You can also choose to augment your dataset by mirroring the image over the y-axis. Shells are mostly dextral or right-handed, so mirroring the images may bias the data a little, but not many people will notice hopefully.
python train.py --batch 2 --size 1024 --checkpoint stylegan2-ffhq-config-f.pt LMDB_PATHI set the batch size to 2 because that is all my poor 1080 GTX can handle before it runs out of memory. From here on out it’s a waiting game. The longer you train the better the model becomes up to a certain point. After training, you can generate samples with the following command. Note that the checkpoint is not stylegan2-ffhq-config-f.pt but your own checkpoint!
python generate.py --sample N_FACES --pics N_PICS --ckpt PATH_CHECKPOINTThis video shows what happens during training. It was trained on a dataset of shell illustrations. Some of you might have noticed Richard Dawkins pop up at the start. This wasn’t a coincidence. Take a lot at projection.py to project your own images into the latent space.
-

Ideophones
“The word ‘onomatopoeia’ is also an onomatopoeia because it’s derived from the sound produced when the word is spoken aloud.” – Ken M
Imagine ringing up a caveman. Utter astonishment on both ends of the line aside – what would you talk about? What could you even talk about? Without the accompanied pantomime, it may even be impossible to convey a message, made up of regular words, that is received in full fidelity in this situation. It’s hard to hold a conversation that transcends time and space solely through the medium of sound.
Certain sounds, however, are and will consist of similar sound waves regardless of whether they are perceived here and now or during the construction of the pyramids of Giza. Like sounds mimicking sounds from nature, like thunder or bird calls. You might instinctively use words like boom or chirp to try to convey the concepts that make these sounds. We call these words onomatopoeia – words that sound like what they describe. And maybe, just maybe, our caveman on the line would get it. Not because he knows English, but because these words carry meaning by resembling the sounds they stand for.
Arecibo message that transcend time, space and species Fart jokes are considered low-hanging fruit to some. But in my opinion, their universality and timelessness are unmatched. From the Japanese in the Edo period to Mozart and Aristophanes, fart jokes are understood by everyone (at least humans) throughout all ages. Even our caveman, who is still on the phone, would most definitely get it if you made the sound.
Sound has power. It can bridge gaps that language sometimes can’t. But it also has its limits.
Take the Arecibo message, for instance—a transmission aimed at alien civilisations. It was sent via radio waves (a type of sound, broadly speaking), but what it carried was a visual message: a bitmap image encoded in binary. An alien would have to reconstruct it visually to make sense of it. Can we use sound to convey a visual message in other ways?

Japanese He-Gassen scroll Wolfgang Kohler observed exactly this when he performed an experiment where he presented people with two figures, one jagged, one rounded, and two names: Takete and Baluba. Participants were asked to match the names to the shapes. A strong preference for calling the rounded shape Baluba and the jagged shape Takete was found. This seems to indicate that humans have to ability to convert a sound into a visual idea.

Takete and Maluma or Maluma and Takete? In 2001, a similar experiment was conducted with Tamil speakers in India. Tamil is rich in ideophones—words that evoke ideas through sound—and these are used regularly in everyday speech. While onomatopoeia typically involves one sound mimicking another (buzz, clang, whoosh), Tamil ideophones go further: sounds can evoke visuals, textures, even emotions.
In contrast, ideophones are relatively rare in most Western languages, though we do have a few: zigzag, twinkle, blob. These words don’t just describe—they sound like the thing they refer to, at least in some intuitive way. The shape of the letters may have something to do with this, but I ain’t no linguist.
Another ideophone is the conceptualisation of a whole personality when hearing a name. ‘Recently’ this has become a meme in the form of Karen. Karen is someone who ate a whole burger and decided not to like it, and now wants to speak to the manager for a refund. Everyone knows a person like this and many people think that the name Karen fits the bill.
But this concept isn’t completely new.
The name Kevin in Germany is associated with a low-achieving person, usually from a lower-class background. It’s a vicious cycle where Kevins, for whom this is not true, are discriminated against and are met with low expectations. It is possible for a Kevin to not be a ‘Kevin’ but the prophecy tends to fulfill itself for these reasons. This is called Kevinismus.

Kevin? (Generated with Stylegan2) Do some names better suit particular faces than others? Do people have a preference?
To test this, I propose the following two surveys. In the first survey, participants are shown 10 faces—5 male and 5 female—of non-existent people, and are asked to come up with a name for each face. These names are then compiled into a list per face, as well as a list of all male and all female names to sample from later.
In the second survey, participants are shown the same 10 faces. Under each face is a list of 5 names: 4 are randomly sampled from the list of all names, and 1 is the most frequently given name for that face in the first survey.
If certain names really do “belong” to certain faces, we should see participants choosing the most frequent name more often than expected by chance.
I posted my survey on r/samplesize and r/namenerds, then prematurely celebrated Burns Night. A few hours later, I checked back in and saw that the form had already racked up over 200 responses! Eventually, the survey would reach an astonishing 1,108 responses before I closed it—perhaps not the most ideal task to pair with a whisky-fueled evening.
After cleaning the data, I quickly ran into a problem: Michael and Mark. Two different faces had these as their most frequent names. To avoid confusion—and potential statistical entanglements—I decided that each face would be assigned its most frequent unique name instead.
So, with that small adjustment made, let me introduce you to the names of the faces… and the results!

- Sarah 58
- Emily 57
- Emma 32
- Hannah 25
- Alice 22
- Sarah 34%
- Carrie 23.1%
- Evelyn 19.9%
- Lynn 11.5%
- Jennifer 11.5%
Honourable mention: Lily Guardian of the Forest. In this case, the data seems to confirm the hypothesis!

- Michael 47
- Mark 47
- Robert 31
- David 31
- John 22
- David 39.6%
- Michael 30.1%
- Enrique 17.7%
- Keith 7.9%
- Jack 4.7%
Honourable mentions: Dan glancer of surreal gallery, Skebep Bernardo. Here, the top choice came second.

- Jessica 40
- Ashley 38
- Karen 31
- Sarah 27
- Brittany 25
- Brittany 39.4%
- Jessica 30.1%
- Caitlyn 21.7%
- Linda 6%
- Mary 2.9%
Honourable mention: Baby Karen. Here, the fifth place was randomly sampled and overtook the top choice. This face has some elements commonly associated with ‘Karen’, mainly the hair-do, but not quite everything. Nevertheless, Karen was the third most frequent entry.

- Mark 92
- John 59
- David 42
- Robert 41
- Michael 35
- Doug 35.7%
- Michael 29.8%
- Rick 27.7%
- Reiner 5.1%
- Kajim 1.6%
Honourable mention: Garret imposer of dreams. I messed up. I should’ve included the top mention in the second survey here, instead, I accidentally entered Michael instead… Nevertheless, Michael does very well in the second survey. One explanation as to why ‘Mark’ was chosen so many times is that this face may resemble Mark Cuban a little (maybe/probably I’m very wrong).

- Mark 55
- John 45
- Peter 35
- David 34
- Michael 31
- Robert 36.7%
- Patrick 27%
- John 25.6%
- Ilgar 8%
- Bob 2.7%
Honourable mentions: Jean Pierre commiter of war crimes, goodwill Jared Kushner. Here I went with John as the name among random samples. ‘John’ was outranked by ‘Robert’ and ‘Patrick’.

- Michelle 31
- Amy 25
- Jennifer 23
- Lisa 23
- Kim 21
- Michelle 52.5%
- Mindy 17.3%
- Helen 13.6%
- Hannah 10.2%
- Sandy 6.4%
Honourable mentions: Supreme leader Annette of the Czech Republic, Mandy Microkrediet. ‘Michelle’ hit it out of the park.

- Gordon 38
- John 27
- Bob 27
- Paul 26
- Robert 24
- Gordon 32.1%
- Peter 29.4%
- Richard 24.2%
- Jason 8.7%
- Joey 5.7%
Honourable mentions: Bob teller of dad jokes, generic chef #5. ‘Gordon’ was a big success. As the last honourable mention alludes to, this face may resemble chef Gordon Ramsey.

- Michael 31
- James 20
- Mark
- Marcus
- George
- Marcus 46.5%
- Eric 22.5%
- James 17.6%
- Seth 10.6%
- Jim 2.8%
Honourable mention: Guptar, possessor of worldly riches. Here I went with ‘James’, which didn’t do so well. ‘Marcus’, the 4th name in the first survey seems to be more fitting.

- Susan 53
- Mary 48
- Linda 43
- Margaret 41
- Barbara 26
- Susan 62.9%
- Gillian 17.4%
- Harriet 13%
- Claire 5.7%
- Savannah 1%
Honourable mention: grandma Deborah conveyer of bed time tales. ‘Susan’ is an enormous success!

- Margaret 42
- Susan 40
- Karen 35
- Mary 34
- Elizabeth 28
- Margaret 48.6%
- Marianne 34.8
- Monica 11.3%
- Megan 3.9%
- Hayley 1.3%
Honourable mention: Grandma Daisy Baker of cookies. Margaret matched up very well. Susan was a good second, and Karen made another appearance.
Bonus rounds
A whopping 89.1% ascribed the name Takete to the jagged shape, reaffirming the original hypothesis. 6.2% found that both names were equally fitting, and 4.7% found Maluma a better fit.

You could have this piece of art on your wall. Click the image to check it out! This is the image that all started it off for me. The fisherman hat, the weird glasses, long sunkissed hair, and inebriated gaze. He strikes me as a ‘the Dude’ type of personality, but I didn’t have a name. From some comments on Reddit, I gathered that he bears a resemblance to the professional boxers Jake and Logan Paul. Personally, I’ve settled on Steve.
- Jake 39
- Logan 35
- Chris 23
- Kyle 23
- Steve 19
Honourable mentions: Geoff, but insists it’s pronounced phonetically, Master Leaf, Floombeard, Broderick, Slappy Whiskers, he calls himself Jagster, Shaggy from Scooby Doo, Broccolingus, Dude McBro the Alpha Surfer of Florida, Skane Skurr, Kyle’s midlife crisis, Lil Soggy, Jimbob, Child Boulder,
Who wouldn’t want this poster on their front door? Click the image to check it out! - Damien 52
- Kevin 29
- Sid 17
- Kyle 13
- Damian 11
Honourable mentions: Shadowfax, Malachi Badson, Tony Pajamas, xX_69gamerjuice69_Xx, Helvetica, Smob, Discount Pennywise
Apparently Damian is a kid and son of the devil in movie Omen. Sid is also famously an evil kid in Toy Story.

- Jason 24
- Seth 23
- James 20
- Chris 16
- Jack 16
6 people correctly found my real name: Rumpelstiltskin. Honourable mentions: Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch, “I’m not mad, I’m just disappointed”, 5/10, “…you […] actually look less real than the other people…”, X Æ 12 ẞ, Facey McFaceFace, Cletus
Thanks, everyone, for participating! The blog is still a work in progress, the story is a bit all over the place, and I probably abused a lot of jargon. The study could have been conducted better, as some pointed out. I agree. I didn’t expect to get enough responses for even one name to be repeated twice. It can luckily easily be set up again. Many seemed to enjoy filling out the names nevertheless. If you have any suggestions, either email me or shoot me a message on Reddit.
-

Colour
The images rendered in the browser from the previous posts don’t look anything like the images made in Chaotica. There are a few reasons for that:
- The number of iterations is comparatively low
- The colours are determined by fixed coordinates
- The previous colour of revisited pixels is not taken into account
- The image is not gamma corrected
- The image is not anti-aliased

Browser renderer 1.0 
Chaotica
The original flame fractal paper mentions that there is no correct number of iterations. Generally, the following maxim holds true: the more the merrier. For educational purposes, I slowed down the iteration speed and rendered each and every step individually. This way you can see how the Chaos game is played out. Once you understand the concept you of course want to speed things up. One of the biggest bottlenecks is rendering pixels at each step. The trade-off is between being able to precisely see what’s being rendered and speed. We generally don’t care about the former as much as by the maxim more iterations usually lead to better renders. But, we’d still like to see some progress. This allows users to cut the rendering process short if the intermediate render is not up to standard. For now, let’s update the image every 100.000 iterations. We can now massively increase the total number of iterations or even let the image render indefinitely shifting the problem to patience. You can experience the trade-off here (normally I’d have the implementation here in the article, but WordPress won’t let me for some reason).

10K 
1M 
1B
The colours in previous images were fixed per pixel coordinates. Whether a pixel is coloured after function x or y doesn’t affect its appearance. By introducing a colour for each function in the system and changing the pixel colour with a function that uses this colour we can change this. Whenever a function is chosen at random, its associated colour is also chosen. We want a pixel to reflect the path of colours it has traversed. One way of doing this is by taking the average between the current colour and the chosen colour. The current colour factor experiences logarithmic decay over time, until it is visited again.
![\[c_{current}=\frac{1}{2}(c_{current} + c_{chosen})\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-dc67afbe11cf26db2fdd955c64db293b_l3.png "Rendered by QuickLaTeX.com")
Some areas of an IFS are visited more often than others. It would be nice if the frequency of visitation was reflected in the image. The first step is recording the frequency a pixel is reached in a buffer. You’ll also need to record the maximum frequency encountered over all pixels. You could then use the frequency divided by the maximum frequency to calculate the alpha channel of a pixel. More visited pixels then become more opaque. The issue with this technique is that certain areas are visited more than others. Looking back at the images from the first paragraph we see that the root of the tree is filled in nicely at a low number of iterations. The result of determining the alpha channel this way is that most parts of the tree would barely be visible. Applying a function that initially grows fast for low values and slow for large values would solve this problem. Taking the base 2 log of the value is a good choice.
After all these improvements the details may still be lost in darkness. To fix this a gamma correction should be applied to the alpha channel. A small gamma under 1.0 makes the image’s dark regions even darker. A gamma above 1.0 makes the image’s dark regions brighter. The gamma correction is done after rendering.
![\[\alpha=\alpha^{\frac{1}{\gamma}}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-c0a1b0932666f0e344adce656b0a5d7e_l3.png "Rendered by QuickLaTeX.com")
There’s one more point left. Anti-aliasing. If you zoom in on the image you’ll see these jagged lines that should be straight. This is called aliasing and it can be fixed. This topic, however, deserves an article on its own.
-

Pythagorean Tree
In high school, I thought that geometry was the most useless subject. It was mainly used to teach mathematical proofs that were supposed to be intuitive. They proved to be quite the opposite. If only my teachers would have shown that you need geometry to make fractals and games. I might have paid more attention. What follows is some simple high school level math which took me several hours to (re-)figure out. Of course, you can skip over the parts you already know.
A B C D E F P T Post affine First, we need Pythagoras' theorem:
 . Which we can rewrite to find the length of the hypotenuse:
. Which we can rewrite to find the length of the hypotenuse:  . The visual interpretation theorem is nicely shown in the image below. The square at the root of the tree is attached to the hypotenuse of a triangle. Let's give the hypotenuse a length of
. The visual interpretation theorem is nicely shown in the image below. The square at the root of the tree is attached to the hypotenuse of a triangle. Let's give the hypotenuse a length of  . The area of the square then becomes
. The area of the square then becomes  . Similarly, the other squares of the triangle are given lengths of
. Similarly, the other squares of the triangle are given lengths of  and
and  . Pythagoras' theorem simply states that the area of the square attached to the hypotenuse is equal to the sum of the area of the squares attached to the rest of the right triangle.
. Pythagoras' theorem simply states that the area of the square attached to the hypotenuse is equal to the sum of the area of the squares attached to the rest of the right triangle.
The theorem is used to calculate the length of child squares. In this application, the lengths are calculated relative to a reference point
 . In the image above is set a the point where the two smaller squares, which I'll call left and right, intersect. The length of the base square is set at 1. The lengths are thus given by:
. In the image above is set a the point where the two smaller squares, which I'll call left and right, intersect. The length of the base square is set at 1. The lengths are thus given by:![\[\text{left length}=\sqrt{x^2+y^2}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-8f5dd941095e40e05c1924b03da514c3_l3.png "Rendered by QuickLaTeX.com")
![\[\text{right length}=\sqrt{(1-x)^2 + y^2}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-8b0988a7bc1fa3804e21aa09a6311949_l3.png "Rendered by QuickLaTeX.com")
To calculate the angle of these child squares in relation to the parent squares we need the SOH-CAH-TOA (SOS-CAS-TOA in Dutch) formulas. These formulas can be rewritten so that they solve for
 . Which will be useful for the purpose of constructing a Pythagorean fractal tree. Here's a quick recap:
. Which will be useful for the purpose of constructing a Pythagorean fractal tree. Here's a quick recap:![\[sin(\theta)=\frac{O}{H}\rightarrow \theta=sin^{-1}(\frac{O}{H})\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-dd71e6e20f95fd444eb751fac7720c34_l3.png "Rendered by QuickLaTeX.com")
![\[cos(\theta)=\frac{A}{H}\rightarrow\theta=cos^{-1}(\frac{A}{H})\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-5f719cd46cb5047249b8ff6bc0819138_l3.png "Rendered by QuickLaTeX.com")
![\[tan(\theta)=\frac{O}{A}\rightarrow\theta=tan^{-1}(\frac{O}{A})\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-847fb1b397e8e7ed4c95abc11c460224_l3.png "Rendered by QuickLaTeX.com")
The angles are calculated as if the squares are turned counter-clockwise. To turn the right square we thus need to apply a negative angle. The angles then become:
![\[\text{left angle}=tan^{-1}(\frac{y}{x}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-2c6b382815154e35722c81d65165782d_l3.png "Rendered by QuickLaTeX.com")
![\[\text{right angle}=-tan^{-1}(\frac{y}{1-x})\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-469d6e1fcb26ec04b72dc257fd1b85d4_l3.png "Rendered by QuickLaTeX.com")
Small digression into IFS formulas. In previous post I only used linear transformations. This means that the
coordinates remain unaltered after they undergo an affine transformation. The squares in the image are achieved by instead of returning the unaltered coordinates, returning coordinates that are uniformly sampled from a bi-unit square shifted 0.5 down and left.![\[\text{linear}(x,y)=(x,y)\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-ebe6ab2591f6dfa73583835a4acbeba8_l3.png "Rendered by QuickLaTeX.com")
![\[\text{square}(x,y)=(r_0 - 0.5, r_1-0.5)\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-a569338fcc62489d12f1002540794340_l3.png "Rendered by QuickLaTeX.com")
Now because the first square is shifted 0.5 down and left we need some additional offsets.
![\[\text{left x offset}= -\frac{1}{2} - \frac{1}{2}cos(180-45-\text{left angle})\sqrt{2\text{(left length)}^2}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-ba6b475a935fb3410f973f4f0586f48b_l3.png "Rendered by QuickLaTeX.com")
![\[\text{left y offset}=-\frac{1}{2} - \frac{1}{2}sin(180-45-\text{left angle})\sqrt{2\text{(left length)}^2}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-9750072e2ea01419b6097eb62396a706_l3.png "Rendered by QuickLaTeX.com")
![\[\text{right x offset}=\frac{1}{2}cos(180-45-\text{right angle})\sqrt{2\text{(left length)}^2} + 1\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-d1da13fd4398f19bf653f93ccef18c64_l3.png "Rendered by QuickLaTeX.com")
![\[\text{right y offset}=-\frac{1}{2}sin(180-45-\text{right angle})\sqrt{2\text{(left length)}^2} - 1\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-5aa155da344921398771af41699197df_l3.png "Rendered by QuickLaTeX.com")
Now all that is left is applying a scaling and rotation matrix. To chain operations simply matrix multiply the matrices.
![\[\text{left affine matrix}=\begin{bmatrix}\text{left length} & 0 \\ 0 & \text{left length}\end{bmatrix}\begin{bmatrix}cos(\text{left angle}) & -sin(\text{left angle}) \\ sin(\text{left angle}) & cos(\text{left angle})\end{bmatrix}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-4c7afe24d7b2b9c5496933332801563f_l3.png "Rendered by QuickLaTeX.com")
![\[\text{right affine matrix}=\begin{bmatrix}\text{right length} & 0 \\ 0 & \text{right length}\end{bmatrix}\begin{bmatrix}cos(\text{right angle}) & -sin(\text{right angle}) \\ sin(\text{right angle}) & cos(\text{right angle})\end{bmatrix}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-8f09e864a35706886a85da1930d58146_l3.png "Rendered by QuickLaTeX.com")
-

Determinism, Chaos and the Lorenz Attractor
Can something be deterministic, yet unpredictable? This is the question at the heart of chaos theory. Previously we’ve played the Chaos Game. If I were to give you a set of initial coordinates and a list of functions that are sequentially applied to these coordinates you would probably be able to eventually figure out the final coordinates. But if the functions were chosen at random you would not. Even though the random function is actually not random, but has an underlying deterministic function. In theory, you could, in practice you won’t.
Another thing that would make it impossible to figure out the final coordinates is when you start at an unknown coordinate. To illustrate this: imagine that someone is listing the digits of Pi. When this person starts out and you witness this start you, will be able to follow along and predict the next digit. You could use a deterministic spigot algorithm to do this. The only thing you need to keep track of is the number of digits the person has already listed. Alternatively, you could use a lookup table. If you were really fanatic, however, you would eventually run out of digits and you will have the use the spigot algorithm to get to more digits.
![\[3.14159 \ldots\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-51f80627dfcaed73a9ee81c99c4d7fd3_l3.png "Rendered by QuickLaTeX.com")
Pi is infinite and transcendental. Every subsequence can occur multiple times. If you were to tune in somewhere in the middle of the person listing its digits you would not be able to predict the next.
![\[\ldots 999999 \ldots\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-4ce6225d7d5649f7c1cbb11bdfbf8a93_l3.png "Rendered by QuickLaTeX.com")
What is the next digit in this sequence? This subsequence of six nines occurs for the first time at the 762nd decimal point, also known as the Feynman point. But it also occurs at the 193034th decimal point. Without any context, there’s no way of knowing after which of the infinite subsequences you are supposed to continue.

Given that you’re far enough into the sequence, the digits of Pi can be seen as a pseudo-random number generator. Many things that appear random have underlying deterministic mechanisms. But due to tuning in at an unknown moment, you might not ever figure out what the underlying mechanism is.
The ancient Greeks also thought about this concept. Democritus illustrated the idea with a story of two servants that are sent to get water from a well at the exact same time. The servants would view their meeting as random. Unbeknownst to them, their masters concocted this evil plan. This story would have been a lot better if the masters had the servants walk out to the middle of nowhere from separate routes at the same time. This would have felt a lot more random to them. Of course, this example isn’t totally the same. The servants can easily deduce the underlying reason. The story would be more representative if the servants were mute and did not know sign language or how to write.
“Nothing occurs at random, but everything for a reason and by necessity”
— LeucippusIf you can’t in any practical way make use of the underlying deterministic mechanism, then what’s the use? To be honest I don’t have an answer to this question. I’m still working on one and it’s hard not to fall into a void of existentialism when thinking about it. It doesn’t matter for any practical applications, but it may alter the way we think about the universe. It may lead to searching for hidden mechanisms that we normally wouldn’t look for because we have always treated them as non-deterministic.
“So, you can conceptualise it, but you cannot measure it. Then, does it matter?”
— Dr. Nikolas SochorakisHere you find an implementation of the Lorenz System. I don’t understand fluid dynamics, nor will I make an attempt to do. However, I will not view the system as being non-deterministic due to my lack of knowledge. Lorenz’s attractor is fully deterministic, yet has the special property that the same coordinates never occur twice. Convince yourself by trying. This algorithm gave rise to the Chaos movement. I highly recommend reading the book Chaos by James Gleick (also the biographer of Richard Feynman) for a comprehensive overview of the history of this field. The system is very sensitive to initial conditions and I encourage you to try out a bunch of settings. Note that the lines seem aliased/jagged. This is due to the rescaling of the Javascript canvas. For a non-aliased image, you can click on the canvas with your right mouse button and press ‘Save image as’.






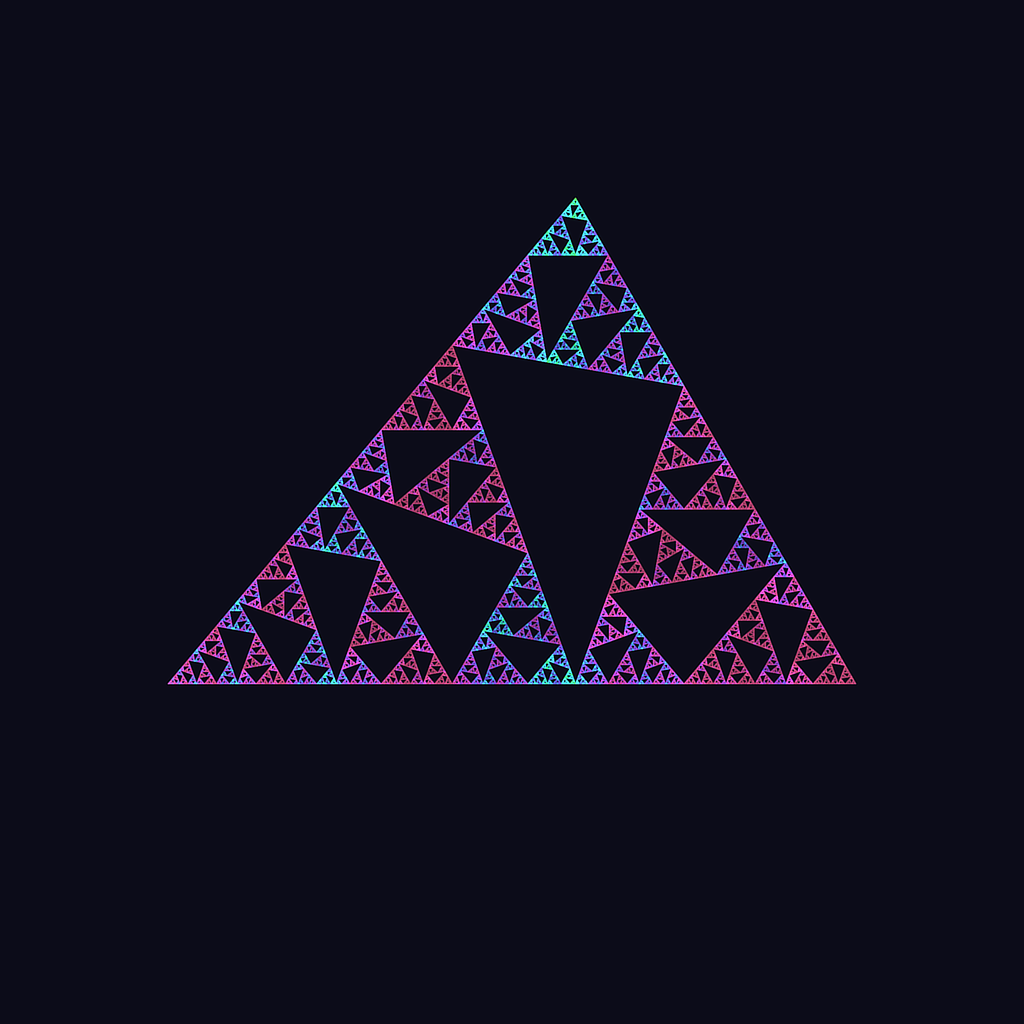
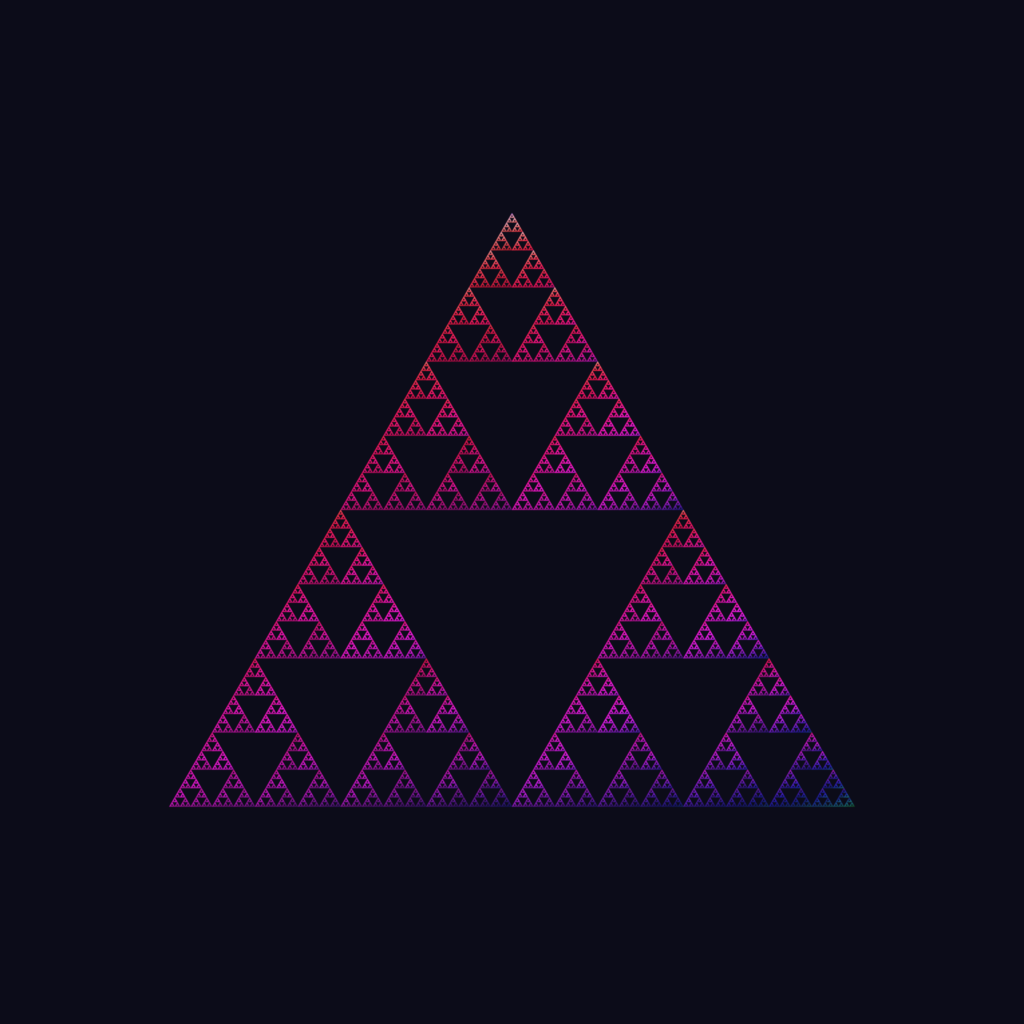
![\[F_0(x,y)=\begin{bmatrix}cos^2(B) & cos(B)sin(B)\\cos(B)sin(B)& -cos^2(B)\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-6e401bd9d4acc7e165d07f7661d88729_l3.png "Rendered by QuickLaTeX.com")
![\[F_1(x,y)=\begin{bmatrix}cos^2(C) & -cos(C)sin(C)\\-cos(C)sin(C) & -cos^2(C)\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}+\begin{bmatrix}sin^2(C)\\cos(C)sin(C)\end{bmatrix}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-d5233d3b3f17bb54512ff90d4debfd98_l3.png "Rendered by QuickLaTeX.com")
![\[F_2(x,y)=\begin{bmatrix}-cos(A)cos(C-B) & cos(A)sin(C-B)\\cos(A)sin(C-B) & cos(A)cos(C-B)\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}+\begin{bmatrix}sin^2(C)\\cos(C)sin(C)\end{bmatrix}\]](https://matigekunstintelligentie.com/wp-content/ql-cache/quicklatex.com-6bb094ed94fd27d994a30eb67e2a38d9_l3.png "Rendered by QuickLaTeX.com")